"oy" is ѹ: 571,753 multi-character confusable pairs nobody is checking for
I tested 190 million two-letter combinations across 245 fonts. 571,753 look like a single character.
Single-character confusables are well-studied. Cyrillic а looks like Latin a; Unicode Technical Report #39 (TR39) covers that. But “rn” looking like “m”? “oy” being geometrically identical to Cyrillic ѹ? No standard covers multi-character confusables systematically.
I tested 190 million bigram-to-character comparisons across 245 fonts. 676 Latin lowercase bigrams against 133,000 single-character targets from every writing system available on macOS. Three-stage geometric filter cascade, no pixel rendering, comparison directly on font vector outlines. 571,753 unique confusable pairs discovered.
This is the first empirical multi-character confusable dataset.
The problem
Unicode Technical Report #39 maintains confusables.txt, the canonical source for character-level visual confusion data. It maps single characters to single targets: Cyrillic о to Latin o, Greek Α to Latin A. It also contains 2,103 multi-character mappings, but those were hand-curated. There is no systematic discovery methodology behind them.
The canonical example everyone cites is “rn” looking like “m” in sans-serif fonts. It appears in every Unicode security talk. Nobody had measured it across fonts until now.
Multi-character confusables are harder to detect than single-character ones. Every detection system today checks individual characters against a lookup table. None check whether a sequence of characters is visually identical to a different single character. The security implications extend beyond domains to every context where Unicode identifiers are displayed: usernames, package names, repository names, file paths. In these contexts, confusable detection either does not exist or only checks single characters.
What changed: geometric comparison on vector outlines
Previous confusable-vision work used pixel rendering + SSIM. That works for single characters but is too expensive for multi-character search. Even after accounting for per-font coverage, the search space is 190 million comparisons. SSIM on rendered pixels is not tractable at that scale.
The new approach compares directly on the font’s vector outlines (Bezier curves), with no rendering step. Two geometric metrics:
Raycasting signatures. Cast parallel rays through glyph outlines from 36 angles, count intersections. This produces a topological fingerprint (1,800 values per glyph) that captures stroke structure, counters, and holes. Precomputed for all 133,000 targets in a signature bank.
Signed Distance Fields (SDF). For pairs that survive raycasting, compute a 128x128 grid where each cell stores the signed distance from that point to the nearest outline edge. Negative values are inside the glyph, positive values are outside. Two SDF grids can then be compared numerically.
L2 distance measures how different two SDF grids are. It is the root-mean-square of per-pixel differences: take the difference at every grid cell, square them, average, and take the square root. Lower means more similar. L2 = 0.000 means the outlines are geometrically identical.
NCC (normalised cross-correlation) measures whether two SDF grids have the same shape, ignoring differences in scale and offset. It correlates the two grids after subtracting their means and normalising by their standard deviations. NCC = 1.0 means identical shape; lower means less similar. NCC is the inverse of L2’s direction: L2 goes down as similarity increases, NCC goes up.
Both metrics appear in the tables throughout this post. L2 is the primary ranking metric; NCC confirms the match quality.
A three-stage filter cascade eliminates 99.07% of comparisons before SDF:
| Stage | Pairs | Remaining |
|---|---|---|
| Total search space | 190,091,200 | 100% |
| After width filter (advance width within 15%) | 69,823,708 | 36.7% |
| After raycasting filter (topological match, threshold 2.0) | 1,768,587 | 0.93% |
| Discoveries (SDF L2 < 15.0) | 1,543,900 | 0.81% |
| Unique bigram-to-target pairs | 571,753 | - |
The width filter alone eliminates 63.3%. Most single characters have advance widths nothing like a two-character sequence. Raycasting catches topological mismatches (different number of counters, strokes, or holes). SDF scoring handles the geometrically close survivors.
This is font-specific by design. The same bigram may be confusable in Helvetica (harmonised metrics) but not in Papyrus (decorative letterforms). The data captures per-font variation.
91 minutes total runtime. 13 worker threads with spatially-indexed SDF computation. Monospace fonts correctly produce zero discoveries (bigrams always have double width). Single-script Noto fonts correctly produce zero cross-script matches.
Headline findings
”oy” is ѹ
L2 = 0.000 in Helvetica. Geometrically identical outlines. Confirmed across 16 fonts.
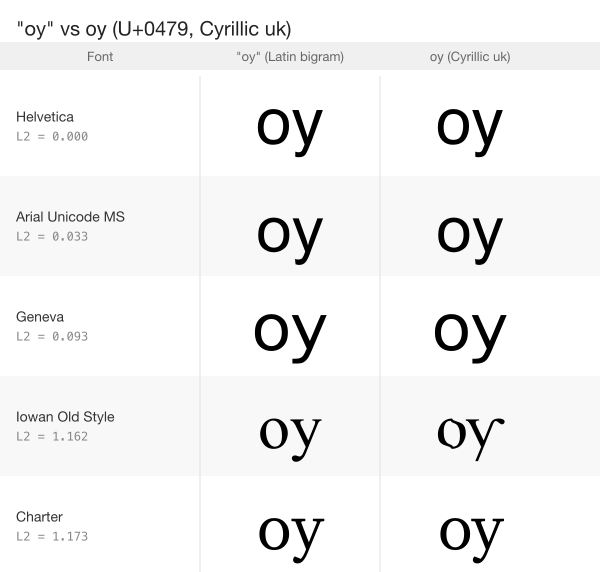
| Font | L2 | NCC |
|---|---|---|
| Helvetica | 0.000 | 1.0000 |
| Arial Unicode MS | 0.033 | 1.0000 |
| Geneva | 0.093 | 1.0000 |
| DIN Condensed | 1.060 | 0.9981 |
| Iowan Old Style | 1.162 | 0.9939 |
| Charter | 1.173 | 0.9949 |
| Helvetica Neue | 1.778 | 0.9886 |
| Superclarendon | 1.801 | 0.9877 |
| Tahoma | 1.888 | 0.9846 |
| Seravek | 1.899 | 0.9842 |
| Microsoft Sans Serif | 2.511 | 0.9744 |
| Times New Roman | 3.004 | 0.9751 |
| Arial | 3.499 | 0.9488 |
| Lucida Grande | 4.091 | 0.9330 |
| Copperplate | 4.479 | 0.9359 |
| Snell Roundhand | 5.397 | 0.9441 |
U+0479 (ѹ) is Cyrillic “uk”, a historical digraph from Old Church Slavonic. Font designers draw it as o+y because that is what it is. The outlines are not merely similar; in Helvetica, they are the same curves.
This is the multi-character analogue of Cyrillic о matching Latin o. But no detection system checks for it.
The IDN attack is tempting to reach for here, but the reality is more nuanced. Three layers of protection exist, each independent:
ICANN Root Zone LGR blocks domain registration. The Cyrillic LGR contains only 86 code points focused on modern living languages. U+0479 is classified as “obsolete (Old Church Slavonic)” and excluded. The Russian and Ukrainian reference LGRs (33 code points each) do not include it either. A domain containing ѹ is not registrable in practice.
TR39 IdentifierStatus blocks well-implemented identifier systems. U+0479 is not listed in IdentifierStatus.txt and defaults to Restricted. Its IdentifierType is explicitly Obsolete (range 0460..0481, 34 Old Church Slavonic characters). But that restriction is based on script classification, not visual similarity. No one restricted it because it looks like “oy”; it was restricted because Old Church Slavonic characters are not in modern use.
confusables.txt does not cover it at all. U+0479 does not appear anywhere in confusables.txt. Not as a source, not as a target, not mapped to “oy” or to anything else. The geometric identity with “oy” has never been catalogued.
The gap is real for any platform that accepts broad Unicode without implementing TR39 restrictions. Usernames, display names, package names, repository names: these contexts typically have no confusable detection, let alone multi-character confusable detection. A username “compoy” vs “compѹ” on a platform with permissive Unicode policies renders identically in Helvetica. The geometric identity is real. The gap it reveals in multi-character confusable detection is real. And if oy/ѹ exists undiscovered between an obsolete Cyrillic character and Latin, what multi-character confusables exist between characters that are in the modern IDN repertoire? That is the argument for extending to Cyrillic and Greek bigrams in the next phase.
The “oy” to ѹ confusable also extends to related bigrams. “ey”, “cy”, “ay”, and “uy” all match ѹ across 15-16 fonts, with the first character’s shape being close enough to the о component.
IPA ligatures: designed to be confusable
These are literally designed as ligatures of their component letters. The pipeline discovers them because the geometric comparison sees no difference between the bigram and the single codepoint.
| Bigram | Target | Codepoint | Best L2 | Fonts |
|---|---|---|---|---|
| ts | ʦ | U+02A6 | 0.805 | 15 |
| ls | ʪ | U+02AA | 0.940 | 3+ |
| dz | ʣ | U+02A3 | 1.226 | 13 |
| lz | ʫ | U+02AB | 1.114 | 3 |
| ds | ʥ | U+02A5 | 3.132 | 9 |
| ts | ʨ | U+02A8 | 1.933 | 15 |
These validate the methodology. If the pipeline did not find IPA ligatures, something would be wrong.
”rn” is “m”
The textbook multi-character confusable, confirmed empirically at L2 = 1.519 in Shree Devanagari 714. Detected across 95 fonts total (the threshold is generous at L2 < 15.0).
The top 10 fonts for “rn” to m:
| Font | L2 | NCC |
|---|---|---|
| Shree Devanagari 714 | 1.519 | 0.9912 |
| InaiMathi | 1.884 | 0.9923 |
| Khmer Sangam MN | 1.996 | 0.9911 |
| System Font | 2.104 | 0.9878 |
| Khmer MN | 2.929 | 0.9871 |
| Arial Narrow | 3.144 | 0.9855 |
| Myanmar Sangam MN | 3.295 | 0.9793 |
| Arial | 3.345 | 0.9608 |
| Bangla Sangam MN | 3.375 | 0.9651 |
| Optima | 3.385 | 0.9613 |
Arial scores L2 = 3.345, not the tightest match. The tightest is Shree Devanagari 714, where the Latin letterforms have particularly uniform stroke widths and minimal kerning between r and n.
The broader “m-like” pattern shows up at the generous L2 < 15.0 threshold, but the quality varies sharply:
| Bigram | Fonts | Best L2 | Mean L2 | Genuine? |
|---|---|---|---|---|
| rn | 95 | 1.519 | 4.097 | Yes, arches merge |
| ra | 102 | 1.907 | 4.097 | Marginal |
| rs | 105 | 2.386 | 4.411 | Threshold noise |
| re | 108 | 3.142 | 4.721 | Threshold noise |
| rc | 107 | 3.130 | 4.807 | Threshold noise |
“re”, “rc”, and “rs” appear in more fonts than “rn” because at high L2 values (7-15), many bigrams have vaguely m-shaped silhouettes. The r’s terminal combined with the next character’s vertical stroke creates two humps. These are not confusable to a human. The genuine signal is in the best-L2 column: “rn” at 1.519 is a real match. “re” at 3.142 is geometrically detectable but visually distinct.
Cross-script: Latin bigrams matching non-Latin singletons
The novel security-relevant findings are bigrams matching characters from different scripts:
“uc”/“as”/“ue”/“oc” match Cyrillic Zhe (Ж, U+0436) in Savoye LET. A decorative script font where the cursive letterforms converge. L2 ranges from 1.428 to 1.702. Font-specific; would not generalise to sans-serif.
“ri” matches Latin n in Telugu Sangam MN and Myanmar Sangam MN. The Indic font’s Latin letterforms make r+i collapse visually to n. L2 = 1.405 and 1.458 respectively.
“ll” matches ǁ (lateral click, U+01C1) in Papyrus (L2 = 0.394) and Arial Unicode MS (L2 = 1.180). In fonts where l has no serifs and consistent spacing, two l’s are geometrically identical to ǁ.
High-confidence cross-font pairs
322 unique bigram-to-target pairs appear in 3 or more fonts with mean L2 below 5.0. The top 20:
| Bigram | Target | Codepoint | Fonts | Best L2 | Mean L2 |
|---|---|---|---|---|---|
| oy | ѹ | U+0479 | 16 | 0.000 | 2.117 |
| ey | ѹ | U+0479 | 16 | 1.189 | 3.020 |
| lb | ℔ | U+2114 | 5 | 1.985 | 3.128 |
| cy | ѹ | U+0479 | 15 | 1.116 | 3.304 |
| ib | ℔ | U+2114 | 5 | 2.111 | 3.331 |
| sx | ꚅ | U+A685 | 7 | 2.782 | 3.449 |
| ts | ʨ | U+02A8 | 15 | 1.933 | 3.521 |
| ds | ʥ | U+02A5 | 9 | 3.132 | 3.575 |
| rp | ȹ | U+0239 | 8 | 2.565 | 3.627 |
| lz | ʫ | U+02AB | 3 | 1.114 | 3.641 |
| da | ʣ | U+02A3 | 6 | 2.776 | 3.693 |
| rb | ȸ | U+0238 | 8 | 2.624 | 3.775 |
| dc | ʣ | U+02A3 | 12 | 3.201 | 3.782 |
| dz | ʣ | U+02A3 | 13 | 1.226 | 3.797 |
| za | ѭ | U+046D | 6 | 3.247 | 3.831 |
| ay | ѹ | U+0479 | 16 | 1.587 | 3.878 |
| re | ᵫ | U+1D6B | 13 | 2.190 | 3.990 |
| is | ʦ | U+02A6 | 16 | 2.254 | 4.036 |
| sa | ꚅ | U+A685 | 7 | 2.551 | 3.959 |
| uy | ѹ | U+0479 | 16 | 2.130 | 4.075 |
Cross-font consistency is the strongest signal for genuine confusables. A pair appearing in 16 fonts with mean L2 under 3 is not noise.
The noise: what the threshold catches that it shouldn’t
Before looking at the score distribution, context on what the generous L2 < 15.0 threshold lets through.
DIN Condensed dominates the discovery list with 30,056 entries. Its top bigrams (“tj”, “lj”, “ij”, “ti”) each match 400+ single-character targets. 18.3% of DIN Condensed discoveries are accented Latin characters (Latin Extended + Greek Extended ranges).
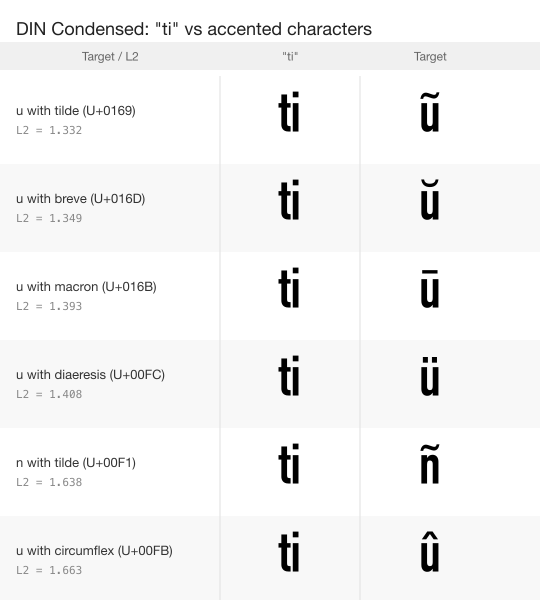
The mechanism: DIN Condensed is a narrow typeface. The thinned-down t+i combination falls within L2 threshold of characters like u with macron, u with breve, a with tilde. Geometrically close in a condensed font. A human would not confuse them. The diacritics are visible, just small.
The median DIN Condensed L2 is 8.021, and only 46 of its 30,056 discoveries have L2 below 2.0. This is a threshold calibration issue, not a pipeline failure. Two improvements would address it: tighter per-font-class thresholds (condensed fonts need stricter L2), or a secondary filter that detects diacritic-sized features in the SDF difference field.
The raw dataset includes all discoveries with their scores. Consumers can filter by L2 < 5.0 for high-confidence pairs, or require cross-font consistency of 3+ fonts.
L2 score distribution
| L2 range | Discoveries | Cumulative % |
|---|---|---|
| 0.0 - 0.5 | 4 | 0.0% |
| 0.5 - 1.0 | 2 | 0.0% |
| 1.0 - 1.5 | 24 | 0.0% |
| 1.5 - 2.0 | 96 | 0.0% |
| 2.0 - 3.0 | 1,029 | 0.1% |
| 3.0 - 4.0 | 5,308 | 0.4% |
| 4.0 - 5.0 | 17,706 | 1.6% |
| 5.0 - 7.0 | 114,500 | 9.0% |
| 7.0 - 10.0 | 497,910 | 41.3% |
| 10.0 - 15.0 | 907,321 | 100.0% |
The distribution is heavily right-skewed. 126 discoveries have L2 below 2.0: near-identical outlines. 24,169 have L2 below 5.0: geometrically close enough that a human might confuse them. The long tail from 7.0 to 15.0 is mostly noise that a tighter threshold would eliminate.
Font coverage
The top 15 fonts by discovery count:
| Font | Discoveries |
|---|---|
| Arial Unicode MS | 141,477 |
| Heiti SC | 103,676 |
| Apple SD Gothic Neo | 91,505 |
| Heiti TC | 78,254 |
| Hiragino Sans | 63,917 |
| Apple Symbols | 58,127 |
| Hiragino Maru Gothic Pro | 55,760 |
| Hiragino Sans GB | 52,713 |
| Hiragino Kaku Gothic Std | 43,877 |
| STIX Two Math | 41,773 |
| Hiragino Kaku Gothic ProN | 40,109 |
| Geneva | 34,922 |
| DIN Condensed | 30,056 |
| Euphemia UCAS | 29,140 |
| Tahoma | 28,003 |
CJK fonts dominate because they contain the most glyphs. Arial Unicode MS has 35,841 targets in the signature bank, so it has the most opportunities for bigram matches. Fonts with zero discoveries: Andale Mono, Courier New, Menlo, Monaco, PT Mono (all monospace), Ayuthaya, Chalkduster, and all 103 Noto single-script fonts.
The monospace result is a built-in validation: bigrams in monospace fonts are always exactly double the width of any single character, so the width filter eliminates 100% of comparisons.
Overlap with TR39
Of the 2,103 multi-character mappings in confusables.txt, 1,848 were scored in the earlier Phase 4 analysis. 15 of those appear as discoveries in Phase 5:
| Mapping | Phase 4 | Phase 5 |
|---|---|---|
| rn to m | Scored | Rediscovered |
| dz to ʣ | Scored | Rediscovered |
| ts to ʦ | Scored | Rediscovered |
| ls to ʪ | Scored | Rediscovered |
| lz to ʫ | Scored | Rediscovered |
| ae to æ | Scored | Rediscovered |
| ae to ӕ | Scored | Rediscovered |
| oe to œ | Scored | Rediscovered |
| ll to ǁ | Scored | Rediscovered |
| ll to װ | Scored | Rediscovered |
| ll to ‖ | Scored | Rediscovered |
| ll to ∥ | Scored | Rediscovered |
| oo to ꚙ | Scored | Rediscovered |
| oo to ∞ | Scored | Rediscovered |
| lt to ₶ | Scored | Rediscovered |
The low overlap (15/1,848) is expected. Phase 4 scored known TR39 multi-character mappings where the source is a single character that decomposes to a multi-character target (e.g. ʣ to “dz”). Phase 5 searches in the opposite direction: Latin bigrams that match single characters (e.g. “dz” to ʣ). The confusables.txt multi-character mappings are mostly decompositions (single char to multi-char sequence), not compositions (multi-char to single char). Only 15 TR39 entries have a Latin-lowercase bigram as their target sequence and a single character as their source that also appears in the Phase 5 signature bank. These are complementary datasets.
The remaining 571,738 Phase 5 pairs have no corresponding entry in TR39’s multi-character mappings. These are novel discoveries.
What this doesn’t cover yet
Latin lowercase only. 676 bigrams from a-z. Mixed case, digits, and cross-script source bigrams (Cyrillic, Greek, Devanagari) are the next phase. The architecture supports this without changes; just wider input loops.
Static kern table only. The pipeline applies kerning from the font’s kern table but does not run a full OpenType shaping engine (GSUB/GPOS). For Latin bigrams this is sufficient. For Arabic, Devanagari, and other complex scripts with contextual shaping, the pipeline would need HarfBuzz integration.
No trigrams. “rn” is a bigram. Longer sequences expand the search space exponentially. The filter cascade can handle it, but the combinatorics need a smarter enumeration strategy than exhaustive search.
macOS system fonts only. 245 fonts from the macOS font library. Windows and Linux font sets differ. The architecture is portable; the font registry is not.
L2 threshold is generous. 15.0 catches genuine confusables and noise. The curated dataset (L2 < 5.0 or cross-font consistency >= 3 fonts) is the recommended consumption format.
What this means for detection systems
No detection system currently checks multi-character confusables at this granularity. TR39’s skeleton algorithm maps sequences to sequences, but the confusable data it draws from has only 2,103 multi-character entries, hand-curated, not discovered empirically.
The dataset enables a new class of check: does this string contain a substring that is geometrically identical to a character from a different script in the user’s font? That is not a lookup-table problem. It is a substring scanning problem, requiring different architecture from current confusable detection.
The practical attack surface is not IDN domains (where ICANN’s Root Zone LGR restricts the repertoire to modern characters) but rather the broader space of Unicode identifiers: usernames on social platforms, package names on registries like npm and PyPI, GitHub repository names, and display names in messaging apps. These contexts typically accept any PVALID character without restricting to a curated repertoire. Multi-character confusable detection does not exist in any of them.
The scored dataset will feed the same weight-based detection as single-character confusables in a future namespace-guard release. Multi-character confusable distance will be available per-font, same as single-character pairs.
How to reproduce
git clone https://github.com/paultendo/confusable-vision
cd confusable-vision
npm install
# Build signature bank (one-time, ~45 min)
npm run build-signature-bank
# Run multi-character discovery (~91 min)
npm run discover-multichar-sdf
# Output: data/output/multichar-discoveries-sdf.jsonlThe JSONL output contains one line per discovery with bigram, target character, target codepoint, font, SDF L2 distance, SDF NCC, and raycasting distance. Filter with jq 'select(.sdfL2 < 5.0)' for high-confidence pairs.
Series context
This post is part of the confusable-vision series:
- Making Unicode risk measurable (research motivation)
- Visual similarity scoring (SSIM + pHash methodology)
- Novel discoveries (903 confusable pairs)
- 148x faster pipeline (performance work)
- Cross-script validation (script family scanning)
- Font-specific maps (per-font confusable weights)
- This post: 571,753 multi-character confusable pairs
- RaySpace methodology (geometric raycasting replaces SSIM and SDF)
- RaySpace prior art (lineage from CT scanners to confusable detection)
- 250K pairs to 102 (IDN relevance filtering)