paultendo
Researching Unicode security, shipping open-source tools, building applied AI systems.
Mostly writing about identifier spoofing, confusable detection and systems designed for measurable behaviour.
Current programme
Unicode identifier security
Cross-script spoofing, confusable detection and measurement.
Browse 17 postsProjects
Elsewhere
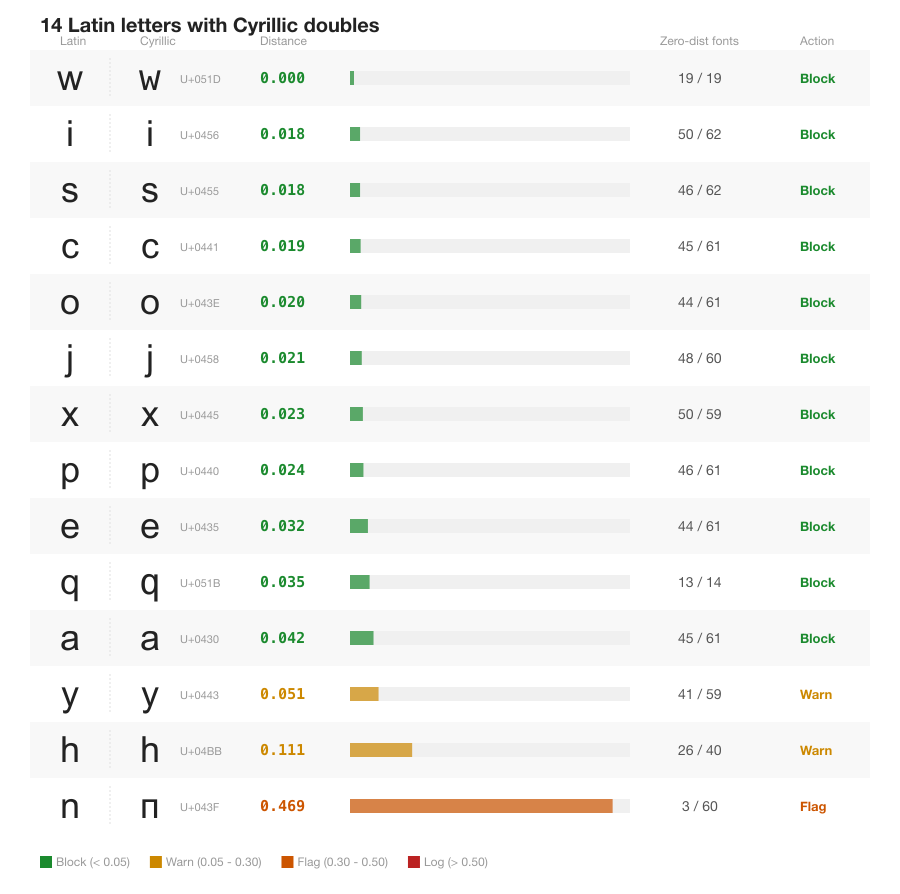
250,000 confusable pairs. 102 that matter for domain names.
Most visual confusables can't appear in domain labels. Filtering by IdentifierType, script rules, and registry variant tables reduces 250K to a short list.
250K → 102
Read the filtering piece
Latest posts
Three threads running through the site: Unicode security research, open-source tooling and applied AI systems.
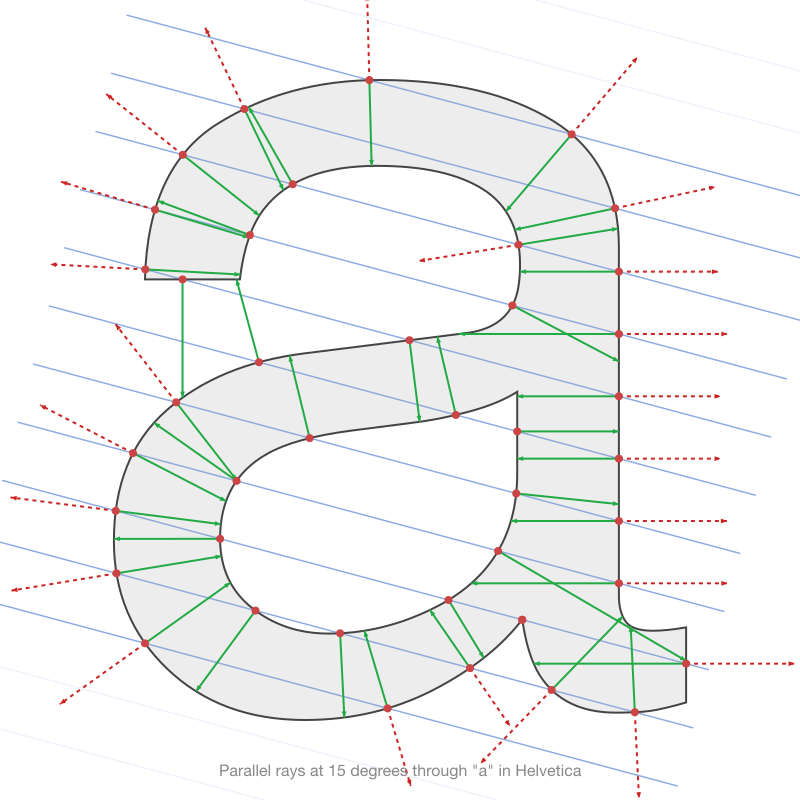
RaySpace: measuring glyph similarity by firing rays through font outlines
No pixels. No neural networks. 250,000 confusable pairs across 245 fonts in 86 minutes.
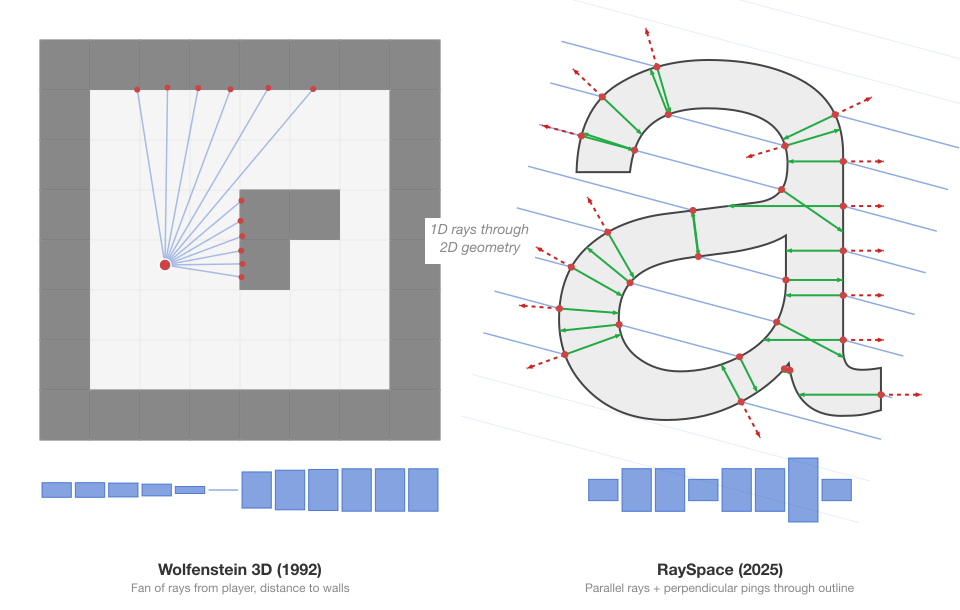
RaySpace is a geometric approach to confusable character detection that compares font vector outlines directly using raycasting. Five layers of signal (intersection counts, positions, crossing angles, ping distances, and ping depth) produce a per-font similarity score without rendering a single pixel.
Read featured post
250,000 confusable pairs. 102 that matter for domain names.
RaySpace found 250,000 unique confusable character pairs. Filtering by IDNA2008, IdentifierType, single-script enforcement, and ICANN registry variant tables reduces that to 3,039 cross-script pairs between Recommended characters, and 102 at high confidence. Here's how the filtering works and where the gaps are.
From CT scanners to confusable characters: the prior art behind RaySpace
RaySpace draws on a century of ray-based geometry techniques, from Radon's uniqueness theorem and Carmack's raycasting to ambient occlusion and acoustic impulse responses. This post maps the full landscape of prior work in confusable detection and shape analysis, and identifies where RaySpace sits in it.
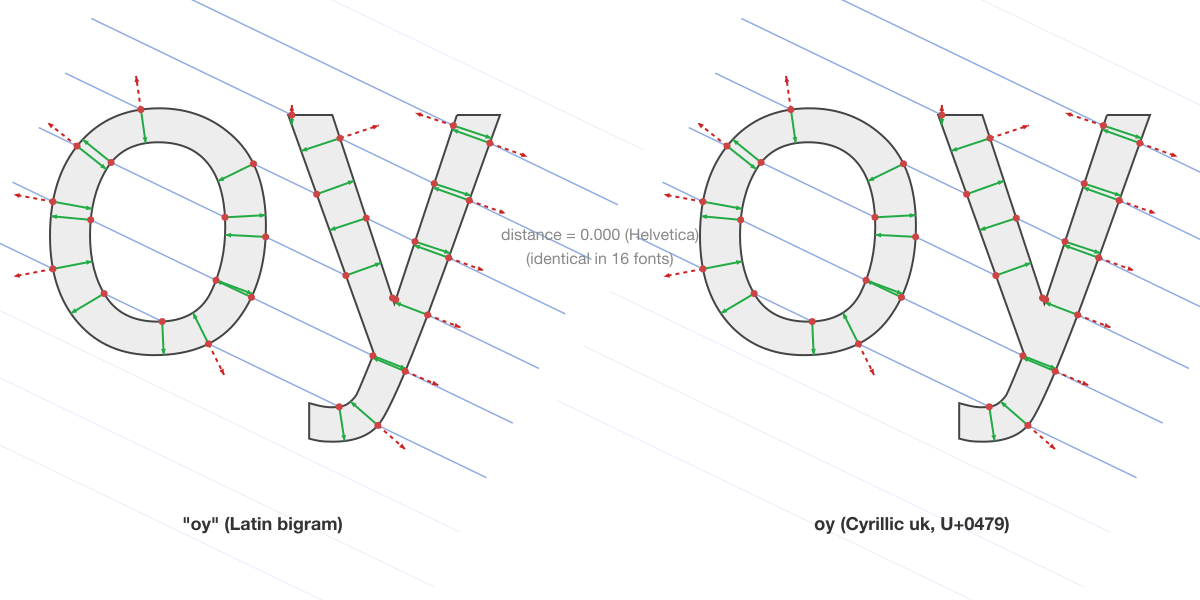
"oy" is ѹ: 571,753 multi-character confusable pairs nobody is checking for
The first systematic, font-specific multi-character confusable dataset. 676 Latin bigrams tested against 133,000 single-character targets across 245 fonts using geometric SDF comparison. 571,753 pairs found, including 'rn' matching 'm' in 95 fonts and 'oy' matching Cyrillic ѹ at distance 0.000.
Your font choice is a security decision
Different fonts make different characters confusable. Font-specific confusable maps give your app precise coverage with 6-30x less data.
248 cross-script confusable pairs that no standard covers
Thai zero looks like Devanagari zero. Georgian S looks like Cyrillic S. Nobody's checking.
I scanned 22,581 characters from 12 scripts against each other across 230 fonts. 248 confusable pairs between non-Latin scripts have no coverage in TR39, ICANN guidelines, or any existing detection system.
Who does confusable detection actually protect?
Unicode's confusable detection maps 6,247 characters to Latin targets, protecting English readers from homograph attacks. But a Russian user spoofed by Greek characters, or an Arabic user spoofed by Syriac, falls outside that coverage. confusable-vision can generate the missing data.
148x faster: rebuilding a Unicode scanning pipeline for cross-script scale
confusable-vision's scoring pipeline went from 8.5 hours to 3.5 minutes through three targeted optimisations: replacing sharp with pure JS bicubic resize, moving SSIM computation to a WASM kernel in worker threads, and switching PNG decoding from sharp to fast-png. All results identical to the original pipeline.
When shape similarity lies: size-ratio artifacts in confusable detection
Confusable detection pipelines normalise characters to a fixed canvas before measuring similarity. This hides natural size differences. We re-rendered 2,203 scored pairs (TR39 baseline + novel discoveries) at their original sizes and found 254 with width or height ratios above 2x.
The new DDoS: Unicode confusables can't fool LLMs, but they can 5x your API bill
130+ API calls, 8 attack types, 4 models. Frontier LLMs read through every pixel-identical substitution. But confusable characters fragment into multi-byte BPE tokens, inflating costs 5x. The comprehension attack fails. The billing attack succeeds.
Can pixel-identical Unicode homoglyphs fool LLM contract review? I tested 8 attack types against GPT-5.2, Claude Sonnet 4.6, and others with 130+ API calls. The models read through every substitution. But confusable characters fragment into multi-byte BPE tokens, turning a failed comprehension attack into a 5x billing attack. Call it Denial of Spend.
Your LLM reads Unicode codepoints, not glyphs. That's an attack surface.
Unicode confusable characters create attack surfaces in LLM pipelines, but not the one everyone expects. Frontier models read through every substitution. The real threats are filter bypass (58.7% success), billing inflation (5.2x token cost), and downstream system failures. No major tokenizer defends against any of them.
28 CJK and Hangul characters look like Latin letters
confusable-vision's Milestone 2b scanned 122,862 CJK, Hangul, Cuneiform, and Egyptian Hieroglyph codepoints against Latin a-z/0-9 across 230 macOS system fonts. 28 novel confusable characters found, all simple geometric primitives.
793 Unicode characters look like Latin letters but aren't (yet) in confusables.txt
confusable-vision's Milestone 2 scanned 23,317 Unicode characters not in TR39 confusables.txt against Latin a-z/0-9 across 230 macOS system fonts. 793 novel high-risk pairs discovered, from 96 different scripts.

I rendered 1,418 Unicode confusable pairs across 230 fonts. Most aren't confusable to the eye.
confusable-vision renders every TR39 confusable pair across 230 macOS system fonts and measures visual similarity with SSIM. 96.5% of confusables.txt is not high-risk, but 82 pairs are pixel-identical in at least one font.
A threat model for Unicode identifier spoofing
Three attack vectors for Unicode identifier spoofing, a survey of twelve detection systems, and a published benchmark corpus for testing your own defences.
Unicode ships one confusable map. You need two.
A survey of how 12 real-world systems apply Unicode confusable detection. None chain NFKC into the confusable lookup. Your confusable map needs to match your normalization strategy.
Lawyers are using AI wrong
The legal profession has adopted AI as a productivity tool when it should be adopting it as an infrastructure layer. Here's what that difference actually means.
I built a will drafting engine. The AI writes almost nothing.
Why a deterministic rule engine beats an LLM for legal document generation — and where the AI actually helps.
Building a rights-aware ingestion pipeline for AI-generated music
AI-generated music deserves proper distribution. I built a browser extension that imports Suno tracks to Oncor with auth separation, idempotent imports, and rights attestation. Here's what we learned.
confusables.txt and NFKC disagree on 31 characters
TR39 and NFKC map 31 characters to different targets. If you build a confusable map for use after NFKC normalization, those entries are unreachable dead code. Here's the full list and how to filter them.
namespace-guard: solving the shared URL namespace problem
Every multi-tenant app has to solve it. I got tired of solving it badly, so I extracted my solution into a library.