28 CJK and Hangul characters look like Latin letters
I scanned 122,862 codepoints from logographic scripts across 230 fonts. Most look nothing like Latin. But 28 do.
In the previous post, I scanned 23,317 identifier-safe Unicode characters against Latin a-z and found 793 novel confusables. That scan deliberately excluded CJK ideographs, Hangul syllables, Cuneiform, Egyptian Hieroglyphs, and other logographic scripts (122,862 codepoints in total) because structurally dense 2D characters were expected to look nothing like thin Latin strokes.
That expectation was mostly right. But not entirely.
The scan
Milestone 2b of confusable-vision runs the same pipeline on every excluded codepoint. Of 122,862 candidates:
- 49,859 (40.6%) have font coverage in at least one of 230 macOS system fonts
- 73,003 (59.4%) have no system font and cannot be rendered
The coverage rate is lower than M2’s 53.8% because CJK Extensions B through I (69,932 codepoints) have minimal system font support. Characters with coverage average only 1.9 fonts each, compared to 7.1 in M2.
Each covered candidate was rendered in its native font(s), normalised to 48x48 greyscale, and compared against all 36 Latin targets (a-z, 0-9) using pHash prefiltering and SSIM scoring. Total: 8,036,479 SSIM comparisons in 46 minutes.
28 characters, 69 pairs
| Band | Count | % | Description |
|---|---|---|---|
| High (>= 0.7) | 69 | 0.004% | Genuinely confusable |
| Medium (0.3-0.7) | 6,564 | 0.4% | Somewhat similar |
| Low (< 0.3) | 1,688,064 | 99.6% | Not visually confusable |
| Total | 1,694,697 |
69 pairs from 28 distinct source characters cross the 0.7 SSIM threshold. All 28 are simple geometric primitives (vertical strokes, circles, and basic cross shapes) that happen to live in ranges otherwise dominated by complex ideographs.
No complex CJK ideograph is confusable with Latin. The 76,891 characters in CJK Extensions A through I produced only 1 high-scoring pair. Hangul Syllables (11,172 characters) produced zero. Dense logographic structure is structurally incompatible with Latin letterforms, exactly as expected.
Where the discoveries are
The 69 pairs concentrate in five ranges:
| Range | High-scoring pairs | What they are |
|---|---|---|
| Egyptian Hieroglyphs | 19 | Simple geometric hieroglyphs (strokes, circles) |
| Cuneiform | 13 | Wedge-mark numerals that are thin vertical strokes |
| CJK Unified Ideographs | 10 | Only the simplest stroke characters (丨, 丄, 丅) |
| CJK Symbols/Bopomofo | 9 | Hangzhou numerals (〡, 〸) and Bopomofo letters |
| Hangul Jamo | 7 | Isolated vowel jamo (ᅵ, ㅣ) rendered as vertical strokes |
The 42,720 characters in CJK Extension B: 1 pair. The 11,172 Hangul Syllables: zero. The 6,592 in CJK Extension A: zero. The dense ideographs are safe.
The vertical strokes
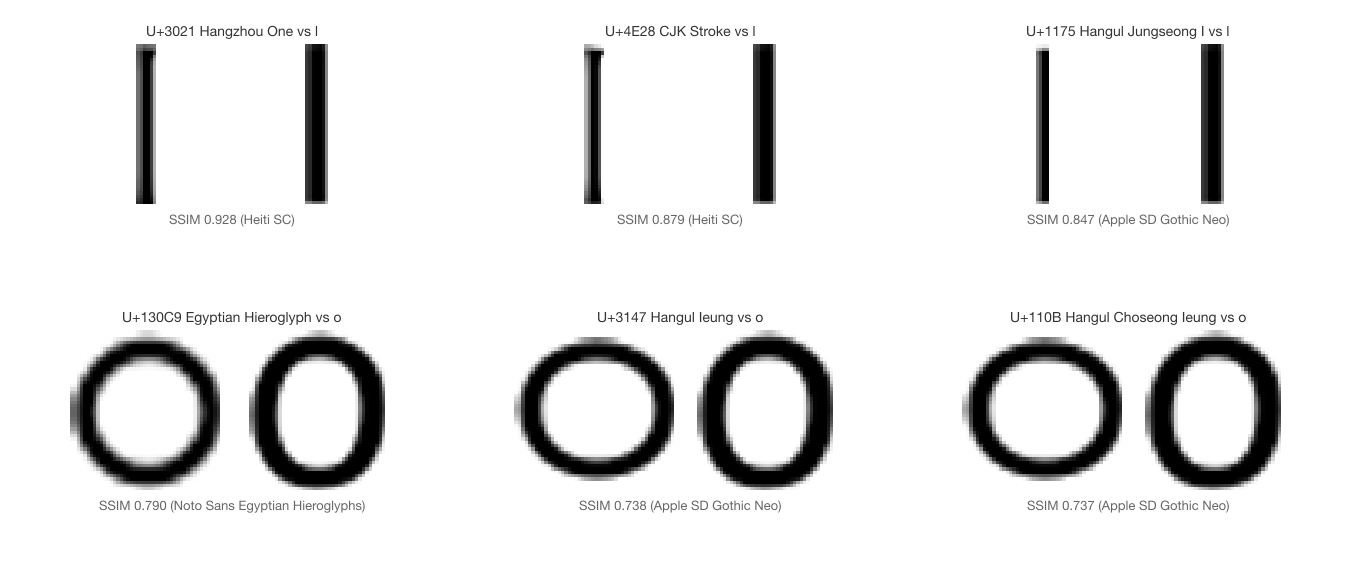
18 of the 28 characters are vertical strokes targeting “l”, “i”, or “j”. This is the same pattern that dominates M2’s discoveries: a single vertical bar is the minimal glyph form shared across writing systems.
| Source | Name | Target | SSIM | Fonts |
|---|---|---|---|---|
| 〡 U+3021 | Hangzhou Numeral One | l | 0.928 | 6 CJK fonts |
| 丨 U+4E28 | CJK Vertical Stroke | l | 0.879 | 10 CJK fonts |
| ᅵ U+1175 | Hangul Jungseong I | l | 0.847 | 2 fonts |
| ㅣ U+3163 | Hangul Letter I | l | 0.847 | 2 fonts |
| ᅵ U+FFDC | Halfwidth Hangul I | l | 0.836 | 1 font |
| 𓏺 U+133FA | Egyptian Hieroglyph | j | 0.831 | 1 font |
| ᆝ U+119D | Hangul Jongseong I | l | 0.825 | 1 font |
| 𒁹 U+12079 | Cuneiform Numeral 1 | l | 0.821 | 1 font |
Hangzhou Numeral One (〡) is the top discovery at 0.928 SSIM against Latin “l”. It is present in 6 CJK system fonts (Heiti SC, Hiragino Sans, Apple SD Gothic Neo, and others), making it the most broadly available M2b find.
The circles
Three characters render as circles that resemble Latin “o”:
| Source | Name | Target | SSIM | Fonts |
|---|---|---|---|---|
| 𓃉 U+130C9 | Egyptian Hieroglyph | o | 0.790 | 1 font |
| ㅇ U+3147 | Hangul Letter Ieung | o | 0.738 | 2 fonts |
| ᄋ U+110B | Hangul Choseong Ieung | o | 0.737 | 2 fonts |
The Korean letter ieung (ㅇ) is a circle used as a null consonant placeholder. An Egyptian hieroglyph independently renders as a circle. Both score above 0.7 against Latin “o”.
Practical risk
Not all 28 characters pose the same threat. The key factor is font availability: an attacker needs the character to render on the victim’s machine.
Higher risk (common CJK fonts):
- 丨 U+4E28, 〡 U+3021: present in 6-10 CJK system fonts. Any machine with CJK language support (standard on macOS, common on Windows) will render these. They target “l” and “i”, which are already high-value spoofing targets.
- ㅣ U+3163, ㅇ U+3147: present in Hangul fonts. Available on any system with Korean language support.
Lower risk (specialised fonts):
- Egyptian hieroglyphs (19 pairs): require Noto Sans Egyptian Hieroglyphs, not a standard system font.
- Cuneiform numerals (13 pairs): require Noto Sans Cuneiform.
52% of M2b discoveries appear in only one font. The CJK stroke characters (丨, 丄, 丅, 〡) are the exception: available in 6-10 fonts, making them the most broadly exploitable finds.
Combined picture
| Metric | M2 (identifier-safe) | M2b (CJK/Hangul/logographic) |
|---|---|---|
| Candidates | 23,317 | 122,862 |
| With font coverage | 12,555 (53.8%) | 49,859 (40.6%) |
| SSIM comparisons | 2,904,376 | 8,036,479 |
| High-risk pairs (>= 0.7) | 793 (0.2%) | 69 (0.004%) |
| Distinct source chars | ~500 | 28 |
| Computation time | 15.5 min | 46 min |
M2b adds 28 characters to the discovery set (3.5% of M2’s count). The hit rate is 50x lower than M2 (0.004% vs 0.2%), confirming that logographic scripts are overwhelmingly incompatible with Latin. The findings are concentrated in edge cases: stroke components, counting marks, and vowel carriers that reduce to the simplest possible geometric forms.
Together, M2 and M2b have now scanned every identifier-safe Unicode character with font coverage against Latin a-z/0-9. The union of their discoveries (793 + 28 = 821 novel confusable characters) represents the complete set of visually similar characters findable by this pipeline on macOS.
How to reproduce
git clone https://github.com/paultendo/confusable-vision
cd confusable-vision
npm install
npx tsx scripts/build-candidates-m2b.ts # 122,862 candidates (~10 min)
npx tsx scripts/build-index-m2b.ts # 236,840 renders (~3 hours)
npx tsx scripts/score-candidates-m2b.ts # 8M SSIM comparisons (~46 min)
npx tsx scripts/extract-m2b.ts # Verification report + discoveriesAll scripts support crash recovery via progress.jsonl and auto-resume on restart. Use --fresh to force a clean start.
The full results are at m2b-discoveries.json and m2b-verification-report.json in the repo (CC-BY-4.0). The technical report is at REPORT.md.
Series context
This is the seventh post in a series on Unicode identifier security:
- confusables.txt and NFKC disagree on 31 characters
- Unicode ships one confusable map. You need two.
- A threat model for Unicode identifier spoofing
- Making Unicode risk measurable
- I rendered 1,418 Unicode confusable pairs across 230 fonts
- 793 novel confusables discovered outside TR39
- This post: 28 CJK/Hangul characters that look like Latin
confusable-vision is MIT-licensed. The discovery data is CC-BY-4.0. namespace-guard (MIT, zero dependencies) integrates these discoveries for anti-spoofing in multi-tenant apps.